Semantic Regexes: Auto-Interpreting LLM Features with a Structured Language
International Conference on Learning Representations, 2026 DOI

Angie Boggust
MIT CSAIL
Donghao Ren
Apple
Yannick Assogba
Apple
Dominik Moritz
Apple

Arvind Satyanarayan
MIT CSAIL
Fred Hohman
Apple
Abstract
Automated interpretability aims to translate large language model (LLM) features into human understandable descriptions. However, natural language feature descriptions can be vague, inconsistent, and require manual relabeling. In response, we introduce semantic regexes, structured language descriptions of LLM features. By combining primitives that capture linguistic and semantic patterns with modifiers for contextualization, composition, and quantification, semantic regexes produce precise and expressive feature descriptions. Across quantitative benchmarks and qualitative analyses, semantic regexes match the accuracy of natural language while yielding more concise and consistent feature descriptions. Their inherent structure affords new types of analyses, including quantifying feature complexity across layers, scaling automated interpretability from insights into individual features to model-wide patterns. Finally, in user studies, we find that semantic regexes help people build accurate mental models of LLM features.
Bibtex
@inproceedings{2026-semantic-regexes,
title = {{Semantic Regexes: Auto-Interpreting LLM Features with a Structured Language}},
author = {Angie Boggust AND Donghao Ren AND Yannick Assogba AND Dominik Moritz AND Arvind Satyanarayan AND Fred Hohman},
booktitle = {International Conference on Learning Representations},
year = {2026},
doi = {10.48550/arXiv.2510.06378},
url = {https://vis.csail.mit.edu/pubs/semantic-regexes}
}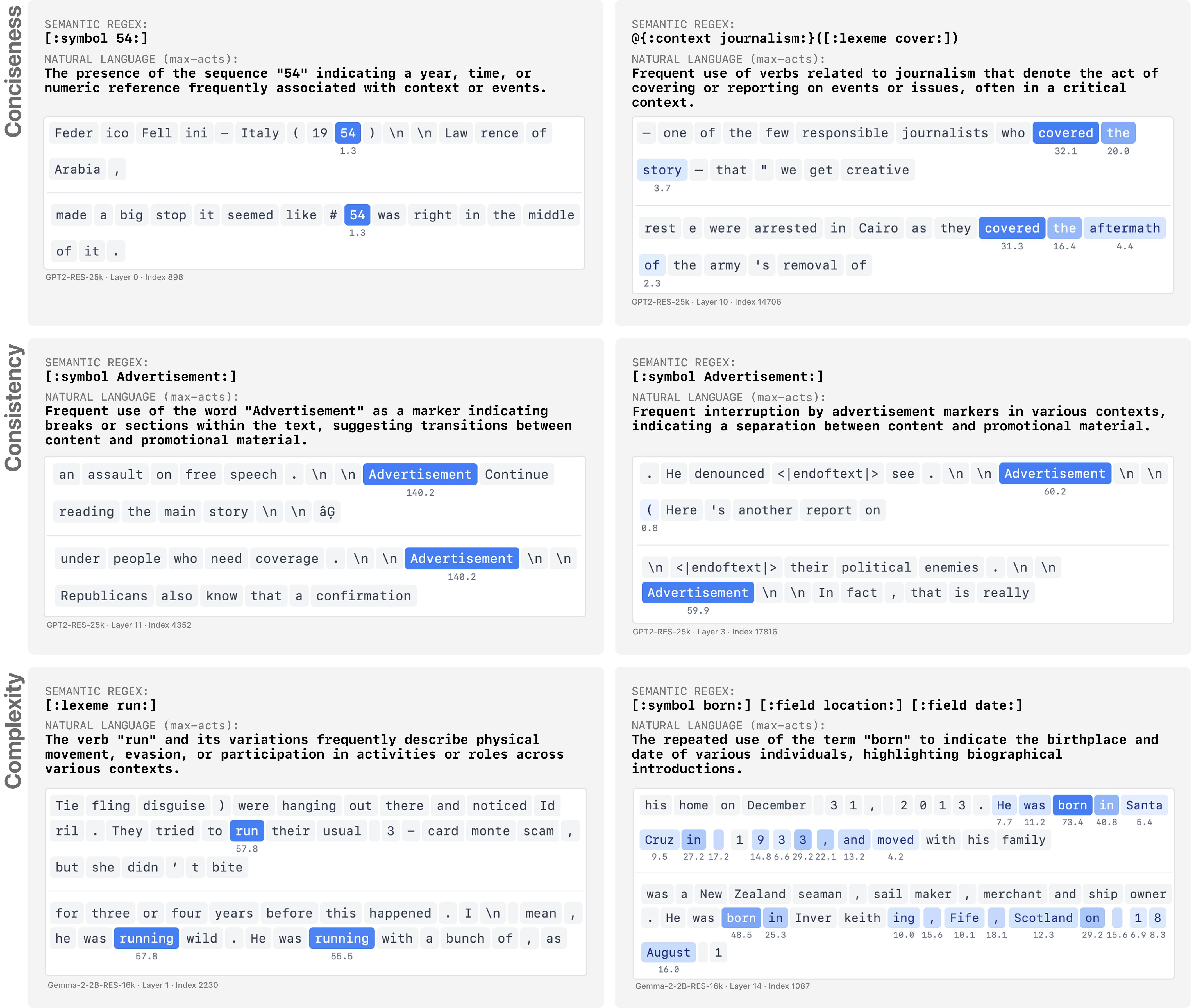
Semantic regexes are often more concise (top), more consistently describe equivalent features (middle), and better reflect feature complexity (bottom) than natural language descriptions.