Learning Structural Semantics for the Web
Stanford Computer Science Technical Report, 2012
Maxine Lim
Stanford University
Ranjitha Kumar
Stanford University

Arvind Satyanarayan
Stanford University
Cesar Torres
Stanford University
Jerry O. Talton
Intel Corporation
Scott R. Klemmer
Stanford University
Abstract
Researchers have long envisioned a Semantic Web, where unstructured Web content is replaced by documents with rich semantic annotations. Unfortunately, this vision has been hampered by the difficulty of acquiring semantic metadata for Web pages. This paper introduces a method for automatically “semantifying” structural page elements: using machine learning to train classifiers that can be applied in a post-hoc fashion. We focus on one popular class of semantic identifiers: those concerned with the structure — or information architecture — of a page. To determine the set of structural semantics to learn and to collect training data for the learning, we gather a large corpus of labeled page elements from a set of online workers. We discuss the results from this collection and demonstrate that our classifiers learn structural semantics in a general way.
Bibtex
@misc{2012-web-structural-semantics,
title = {{Learning Structural Semantics for the Web}},
author = {Maxine Lim AND Ranjitha Kumar AND Arvind Satyanarayan AND Cesar Torres AND Jerry O. Talton AND Scott R. Klemmer},
institute = {Stanford Computer Science Technical Report},
year = {2012},
url = {https://vis.csail.mit.edu/pubs/web-structural-semantics}
}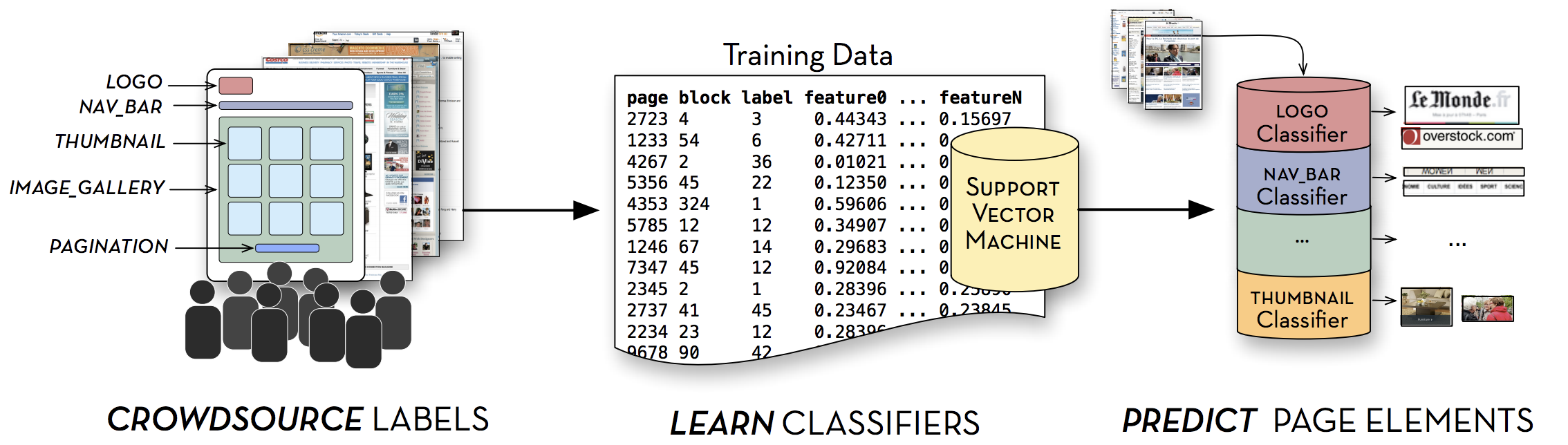
The pipeline for learning structural semantic classifiers for the Web. First, a large set of labeled page elements are collected from online workers. Next, these labels are used to train a set of regularized support vector classification SVMs. These classifiers are then used to identify semantic elements in new pages.