Intuitively Assessing ML Model Reliability through Example-Based Explanations and Editing Model Inputs
ACM Intelligent User Interfaces (IUI), 2022 DOI

Harini Suresh
MIT CSAIL
Kathleen M. Lewis
MIT CSAIL
John V. Guttag
MIT CSAIL

Arvind Satyanarayan
MIT CSAIL
Abstract
Interpretability methods aim to help users build trust in and understand the capabilities of machine learning models. However, existing approaches often rely on abstract, complex visualizations that poorly map to the task at hand or require non-trivial ML expertise to interpret. Here, we present two interface modules that facilitate intuitively assessing model reliability. To help users better characterize and reason about a model’s uncertainty, we visualize raw and aggregate information about a given input’s nearest neighbors. Using an interactive editor, users can manipulate this input in semantically-meaningful ways, determine the effect on the output, and compare against their prior expectations. We evaluate our approach using an electrocardiogram beat classification case study. Compared to a baseline feature importance interface, we find that 14 physicians are better able to align the model’s uncertainty with domain-relevant factors and build intuition about its capabilities and limitations.
Bibtex
@inproceedings{2022-knnviz,
title = {{Intuitively Assessing ML Model Reliability through Example-Based Explanations and Editing Model Inputs}},
author = {Harini Suresh AND Kathleen M. Lewis AND John V. Guttag AND Arvind Satyanarayan},
booktitle = {ACM Intelligent User Interfaces (IUI)},
year = {2022},
doi = {10.1145/3490099.3511160},
url = {https://vis.csail.mit.edu/pubs/knnviz}
}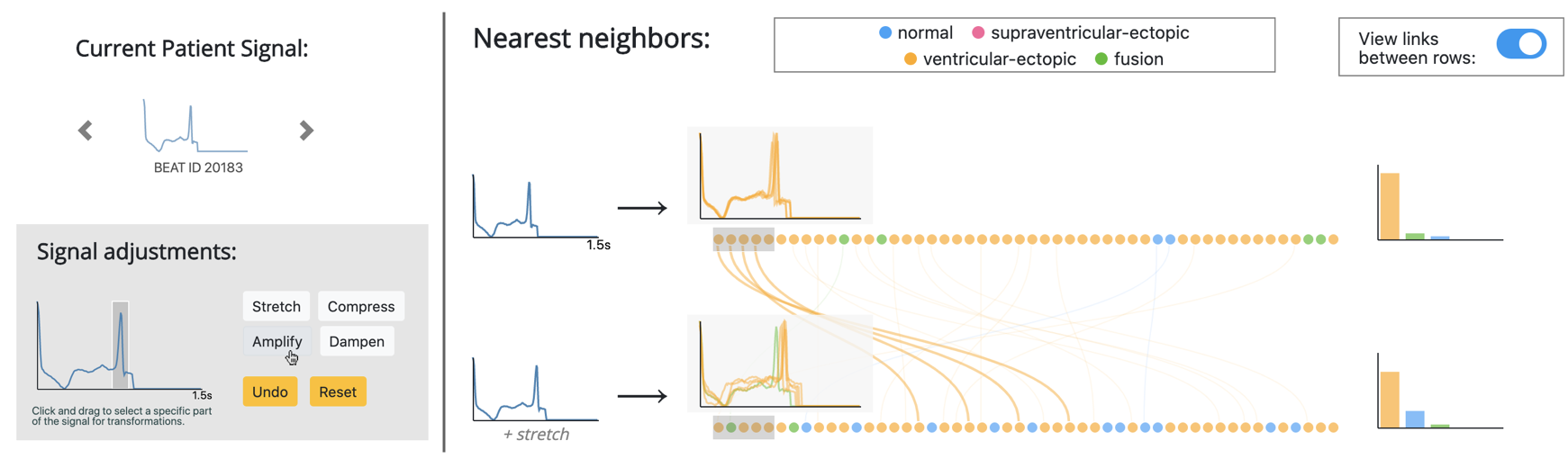
An example of the proposed interface for an electrocardiogram (ECG) case study. The output of the machine learning model consists of raw and aggregate information about the input's nearest neighbors. With the editor in the bottom left, the user can apply semantically-meaningful manipulations to the input and see how the output changes.