


 Long Description
Long Description
Abstract
Natural language descriptions sometimes accompany visualizations to better communicate and contextualize their insights, and to improve their accessibility for readers with disabilities. However, it is difficult to evaluate the usefulness of these descriptions, and how effectively they improve access to meaningful information, because we have little understanding of the semantic content they convey, and how different readers receive this content. In response, we introduce a conceptual model for the semantic content conveyed by natural language descriptions of visualizations. Developed through a grounded theory analysis of 2,147 sentences, our model spans four levels of semantic content: enumerating visualization construction properties (e.g., marks and encodings); reporting statistical concepts and relations (e.g., extrema and correlations); identifying perceptual and cognitive phenomena (e.g., complex trends and patterns); and elucidating domain-specific insights (e.g., social and political context). To demonstrate how our model can be applied to evaluate the effectiveness of visualization descriptions, we conduct a mixed-methods evaluation with 30 blind and 90 sighted readers, and find that these reader groups differ significantly on which semantic content they rank as most useful. Together, our model and findings suggest that access to meaningful information is strongly reader-specific, and that research in automatic visualization captioning should orient toward descriptions that more richly communicate overall trends and statistics, sensitive to reader preferences. Our work further opens a space of research on natural language as a data interface coequal with visualization.
1 Introduction
The proliferation of visualizations during the COVID-19 pandemic has underscored their double-edged potential: efficiently communicating critical public health information — as with the immediately-canonical “Flatten the Curve” chart (Fig. Teaser) — while simultaneously excluding people with disabilities.
“
Predating the pandemic, publishers and education specialists have long suggested best practices for accessible visual media, including guidelines for tactile graphics [41] and for describing “complex images” in natural language [99, 39]. While valuable, visualization authors have yet to broadly adopt these practices, for lack of experience with accessible media, if not a lack of attention and resources. Contemporary visualization research has primarily attended to color vision deficiency [21, 77, 79], and has only recently begun to engage with non-visual alternatives [25, 67] and with accessibility broadly [53, 105]. Parallel to these efforts, computer science researchers have been grappling with the engineering problem of automatically generating chart captions [27, 78, 84]. While well-intentioned, these methods usually neither consult existing accessibility guidelines, nor do they evaluate their results empirically with their intended readership. As a result, it is difficult to know how useful (or not) the resultant captions are, or how effectively they improve access to meaningful information.
In this paper, we make a two-fold contribution. First, we extend existing accessibility guidelines by introducing a conceptual model for categorizing and comparing the semantic content conveyed by natural language descriptions of visualizations. Developed through a grounded theory analysis of 2,147 natural language sentences, authored by over 120 participants in an online study (§ 3), our model spans four levels of semantic content: enumerating visualization construction properties (e.g., marks and encodings); reporting statistical concepts and relations (e.g., extrema and correlations); identifying perceptual and cognitive phenomena (e.g., complex trends and patterns); and elucidating domain-specific insights (e.g., social and political context) (§ 4). Second, we demonstrate how this model can be applied to evaluate the effectiveness of visualization descriptions, by comparing different semantic content levels and reader groups. We conduct a mixed-methods evaluation in which a group of 30 blind and 90 sighted readers rank the usefulness of descriptions authored at varying content levels (§ 5). Analyzing the resultant 3,600 ranked descriptions, we find significant differences in the content favored by these reader groups: while both groups generally prefer mid-level semantic content, they sharply diverge in their rankings of both the lowest and highest levels of our model.
These findings, contextualized by readers’ open-ended feedback, suggest that access to meaningful information is strongly reader-specific, and that captions for blind readers should aim to convey a chart’s trends and statistics, rather than solely detailing its low-level design elements or high-level insights.
Our model of semantic content is not only
2 Related Work
Multiple visualization-adjacent literatures have studied methods for describing charts and graphics through natural language — including accessible media research, Human-Computer Interaction (HCI), Computer Vision (CV), and Natural Language Processing (NLP). But, these various efforts have been largely siloed from one another, adopting divergent methods and terminologies (e.g., the terms “caption” and “description” are used inconsistently). Here, we survey the diverse terrain of literatures intersecting visualization and natural language.
2.1 Automatic Methods for Visualization Captioning
Automatic methods for generating visualization captions broadly fall into two categories: those using CV and NLP methods when the chart is a rasterized image (e.g., jpegs or pngs); and those using structured specifications of the chart’s construction (e.g., grammars of graphics).
2.1.1 Computer Vision and Natural Language Processing
Analogous to the long-standing CV and NLP problem of automatically captioning photographic images [64, 58, 48], recent work on visualization captioning has aimed to automatically generate accurate and descriptive natural language sentences for charts [22, 24, 23, 6, 78, 59, 83].
Following the encoder-decoder framework of statistical machine translation [98, 107], these approaches usually take rasterized images of visualizations as input to a CV model (the encoder), which learns the visually salient features for outputting a relevant caption via a language model (the decoder).
Training data consists of ⟨chart, caption⟩ pairs, collected via web-scraping and crowdsourcing [84], or created synthetically from pre-defined sentence templates [47].
While these approaches are well-intentioned, in aiming to address the engineering problem of
2.1.2 Structured Visualization Specifications
In contrast to rasterized images of visualizations, chart templates [96], component-based architectures [38], and grammars of graphics [87] provide not only a structured representation of the visualization’s construction, but typically render the visualization in a structured manner as well. For instance, most of these approaches either render the output visualization as Scalable Vector Graphics (SVG) or provide a scenegraph API. Unfortunately, these output representations lose many of the semantics of the structured input (e.g., which elements correspond to axes and legends, or how nesting corresponds to visual perception). As a result, most present-day visualizations are inaccessible to people who navigate the web using screen readers. For example, using Apple’s VoiceOver to read D3 charts rendered as SVG usually outputs an inscrutable mess of screen coordinates and shape rendering properties. Visualization toolkits can ameliorate this by leveraging their structured input to automatically add Accessible Rich Internet Application (ARIA) attributes to appropriate output elements, in compliance with the World Wide Web Consortium (W3C)’s Web Accessibility Initiative (WAI) guidelines [99]. Moreover, this structured input representation can also simplify automatically generating natural language captions through template-based mechanisms, as we discuss in § 4.1.
2.2 Accessible Media and Human-Computer Interaction
While automatic methods researchers often note accessibility as a worthy motivation [27, 78, 84, 83, 30, 31], evidently few have collaborated directly with disabled people [25, 71] or consulted existing accessibility guidelines [67]. Doing so is more common to HCI and accessible media literatures [73, 91], which broadly separate into two categories corresponding to the relative expertise of the description authors: those authored by experts (e.g., publishers of accessible media) and those authored by non-experts (e.g., via crowdsourcing or online platforms).
2.2.1 Descriptions Authored by Experts
Publishers have developed guidelines for describing graphics appearing in science, technology, engineering, and math (STEM) materials [39, 9].
Developed by and for authors with some expert accessibility knowledge, these guidelines provide best practices for conveying visualized content in traditional media (e.g., printed textbooks, audio books, and tactile graphics).
But, many of their prescriptions — particularly those relating to the
2.2.2 Descriptions Authored by Non-Experts
Frequently employed in HCI and visualization research, crowdsourcing is a technique whereby remote non-experts complete tasks currently infeasible for automatic methods, with applications to online accessibility [13], as well as remote description services like
2.3 Natural Language Hierarchies and Interfaces
Apart from the above methods for generating descriptions, prior work has adopted linguistics-inspired framings to elucidate how natural language is used to describe — as well as interact with — visualizations.
2.3.1 Using Natural Language to Describe Visualizations
Demir et al. have proposed a hierarchy of six syntactic complexity levels corresponding to a set of propositions that might be conveyed by bar charts [27].
Our model differs in that it orders
2.3.2 Using Natural Language to Interact with Visualizations
Adjacently, there is a breadth of work on Natural Language Interfaces (NLIs) for constructing and exploring visualizations [75, 42, 90, 50].
While our model primarily considers the natural language sentences that are
3 Constructing the Model: Employing the Grounded Theory Methodology
To construct our model of semantic content we conducted a multi-stage process, following the
3.1 Initial Open Coding
We began gathering preliminary data by searching for descriptions accompanying visualizations in journalistic publications (including the websites of
Analyzing these preliminary data, we proceeded to the next stage in the grounded theory method: forming
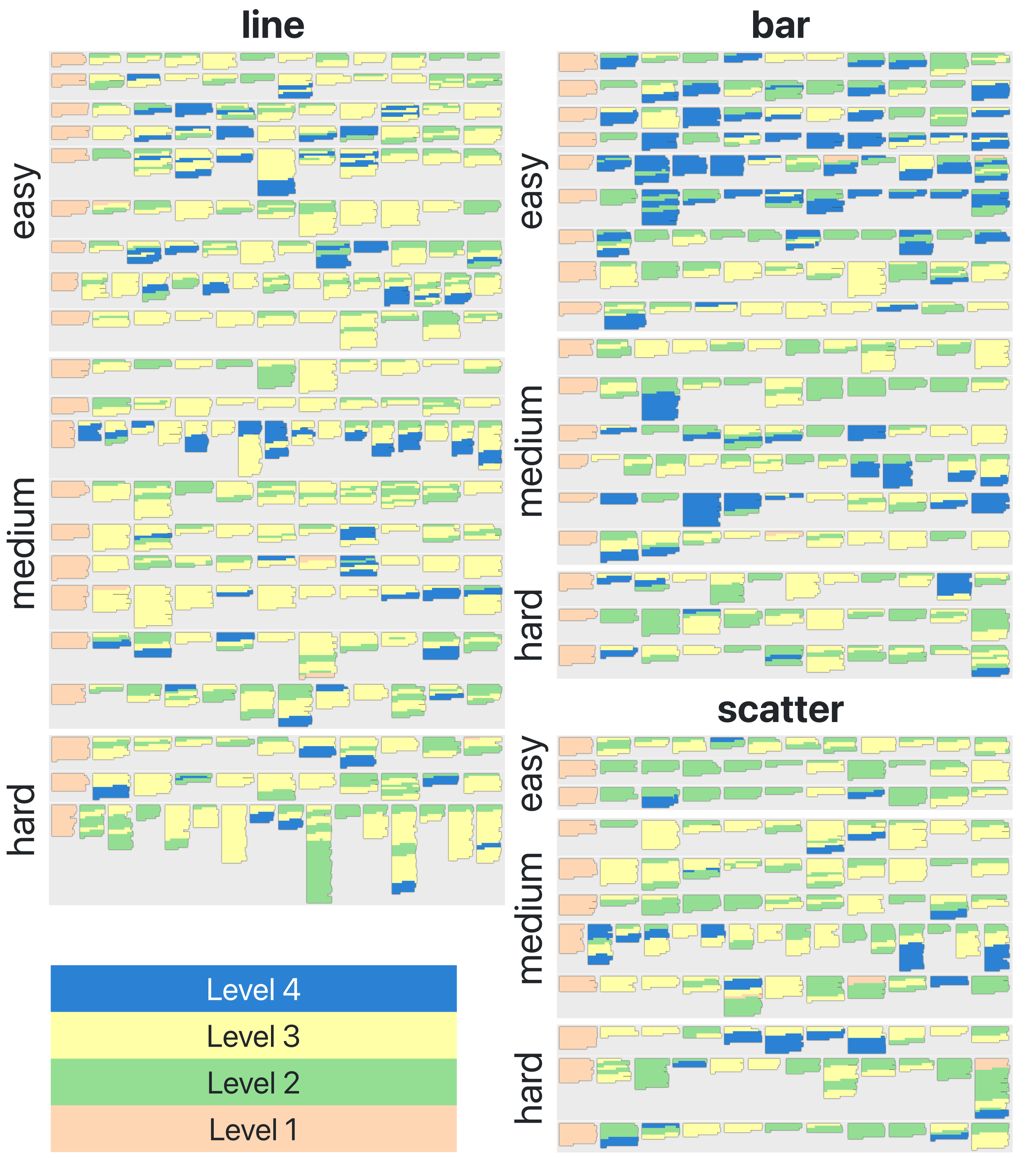
(N.b., each column sums to 50.)
| chart type | topic | difficulty | |||
|---|---|---|---|---|---|
| bar | 18 | academic | 15 | easy | 21 |
| line | 21 | business | 18 | medium | 20 |
| scatter | 11 | journalism | 17 | hard | 9 |
3.2 Gathering A Corpus
The prior inductive and empirical process resulted in a set of preliminary content categories. To test their robustness, and to further refine them, we conducted an online survey to gather a larger-scale corpus of 582 visualization descriptions comprised of 2,147 sentences.
3.2.1 Survey Design
We first curated a set of 50 visualizations drawn from the MassVis dataset [16, 15], Quartz’s Atlas visualization platform [81], examples from the Vega-Lite gallery [87], and the aforementioned journalistic publications.
We organized these visualizations along three dimensions: the visualization
In the survey interface, participants were shown a single, randomly-selected visualization at a time, and prompted to describe it in complete English sentences.
In our preliminary data collection (§ 3.1), we found that without explicit prompting participants were likely to provide only brief and minimally informative descriptions (e.g., sometimes simply repeating the chart title and axis labels).
Thus, to mitigate against this outcome, and to elicit richer semantic content, we explicitly instructed participants to author descriptions that did not
 Long Description
Long Description
3.2.2 Survey Results
We recruited 120 survey participants through the
In summary, the entire grounded theory process resulted in four distinct semantic content categories, which we organize into
4 A Four-Level Model of Semantic Content
| level number | level keywords | semantic content | computational considerations |
|---|---|---|---|
| Level 4 | contextual and domain-specific |
|
contextual knowledge and domain-specific expertise ( |
| Level 3 | perceptual and cognitive |
|
reference to the rendered visualization and “common knowledge” ( |
| Level 2 | statistical and relational |
|
access to the visualization specification or backing dataset ( |
| Level 1 | elemental and encoded |
|
access to the visualization specification or rasterized image ( |
Our grounded theory process yielded a four-level model of semantic content for the natural language description of visualizations.
In the following subsections, we introduce the levels of the model and provide example sentences for each.
Table 2 summarizes the levels, and Table 3 shows example visualizations from our corpus and corresponding descriptions, color coded according to the model’s color scale.
Additionally, we offer practical
4.1 Level 1: Elemental and Encoded Properties
At the first level, there are sentences whose semantic content refers to elemental and encoded properties of the visualization (i.e., the visual components that comprise a graphical representation’s design and construction). These include the chart type (bar chart, line graph, scatter plot, etc.), its title and legend, its encoding channels, axis labels, and the axis scales. Consider the following sentence (Table 3.A.1).
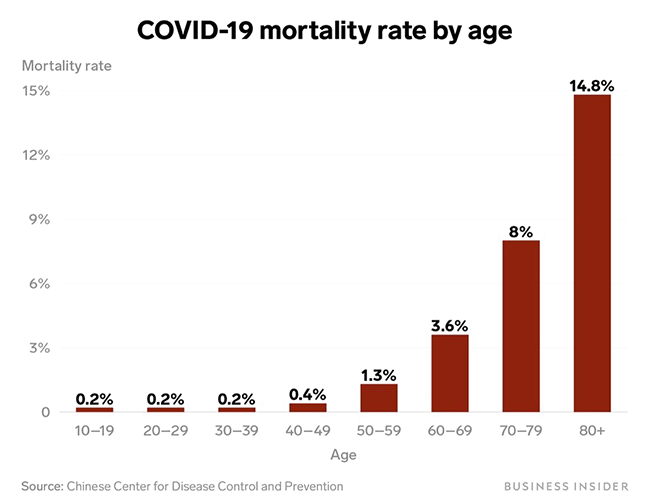
Mortality rate is plotted on the vertical y-axis from 0 to 15%. Age is plotted on the horizontal x-axis in bins: 10-19, 20-29, 30-39, 40-49, 50-59, 60-69, 70-79, 80+.
This sentence “reads off” the axis labels and scales as they appear in the bar chart, with no additional synthesizing or interpretation.
Sentences such as this are placed at the lowest level in the model because they refer to content that is
“
This is a [chart-type] entitled [chart-title]. [y-encoding] is plotted on the vertical y-axis from [y-min] to [y-max]. [x-encoding] is plotted on the horizontal x-axis from [x-min] to [x-max] .”
And similarly, for other sentence templates and elemental properties encoded in the visualization’s structured specification. If the structured specification is not available, however, or if it does not follow a declarative grammar, then CV and NLP methods have also shown promise when applied to rasterized visualization images (e.g., jpegs or pngs). For example, recent work has shown that Level 1 semantic content can be feasibly generated provided an appropriate training dataset of pre-defined sentence templates [47], or by extracting a visualization’s structured specification from a rasterized visualization image [81].
4.2 Level 2: Statistical Concepts and Relations
At the second level, there are sentences whose semantic content refers to abstract statistical concepts and relations that are latent the visualization’s backing dataset.
This content conveys computable descriptive statistics (such as mean, standard deviation, extrema, correlations) — what have sometimes been referred to as “data facts” because they are “objectively” present within a given dataset [92, 100] (as opposed to primarily observed via visualization, which affords more opportunities for subjective interpretation).
In addition to these statistics, Level 2 content includes
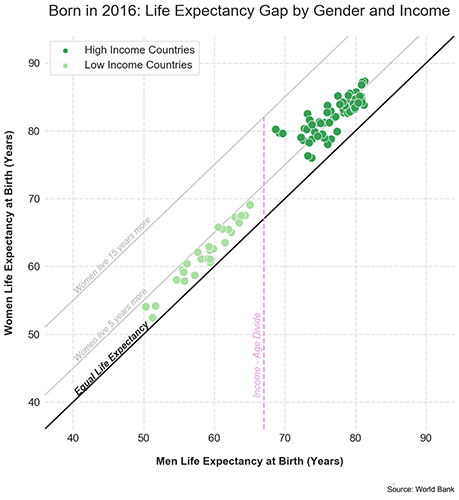
For low income countries, the average life expectancy is 60 years for men and 65 years for women. For high income countries, the average life expectancy is 77 years for men and 82 years for women.
These two sentences refer to a statistical property: the computed mean of the life expectancy of a population, faceted by gender and country income-level. Consider another example (Table 3.A.2).
The highest COVID-19 mortality rate is in the 80+ age range, while the lowest mortality rate is in 10-19, 20-29, 30-39, sharing the same rate.
Although this sentence is more complex, it nevertheless resides at Level 2. It refers to the
| visualization | description | |
|---|---|---|
| A |
[bar, easy, journalism]
|
[1, L1] This is a vertical bar chart entitled “COVID-19 mortality rate by age” that plots Mortality rate by Age. Mortality rate is plotted on the vertical y-axis from 0 to 15%. Age is plotted on the horizontal x-axis in bins: 10-19, 20-29, 30-39, 40-49, 50-59, 60-69, 70-79, 80+. [2, L2] The highest COVID-19 mortality rate is in the 80+ age range, while the lowest mortality rate is in 10-19, 20-29, 30-39, sharing the same rate. [3, L3] COVID-19 mortality rate does not linearly correspond to the demographic age. [4, L3] The mortality rate increases with age, especially around 40-49 years and upwards. [5, L4] This relates to people’s decrease in their immunity and the increase of co-morbidity with age. [6, L3] The mortality rate increases exponentially with older people. [7, L2] There is no difference in the mortality rate in the range between the age of 10 and 39. [8, L3] The range of ages between 60 and 80+ are more affected by COVID-19. [9, L4] We can observe that the mortality rate is higher starting at 50 years old due to many complications prior. [10, L3] As we decrease the age, we also decrease the values in mortality by a lot, almost to none. |
| B |
[line, medium, business]
|
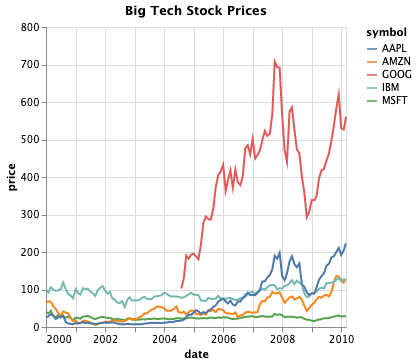
[1, L1] This is a multi-line chart entitled “Big Tech Stock Prices” that plots price by date. The corporations include AAPL (Apple), AMZN (Amazon), GOOG (Google), IBM (IBM), and MSFT (Microsoft). The years are plotted on the horizontal x-axis from 2000 to 2010 with an increment of 2 years. The prices are plotted on the vertical y-axis from 0 to 800 with an increment of 200. [2, L2] GOOG has the greatest price over time. MSFT has the lowest price over time. [3, L3] Prices of particular Big Tech corporations seem to fluctuate but nevertheless increase over time. Years 2008-2009 are exceptions as we can see an extreme drop in prices of all given corporations. [4, L4] The big drop in prices was caused by financial crisis of 2007-2008. The crisis culminated with the bankruptcy of Lehman Brothers on September 15, 2008 and an international banking crisis. [5, L4] At the beginning of 2008, every of this stock price went down, likely due to the financial crisis. [6, L3] Then they have risen again and dropped again, more so than previously. [7, L2] GOOG has the highest price over the years. MSFT has the lowest price over the years. [8, L3] GOOG quickly became the richest one of the Big Tech corporations. [9, L4] GOOG had experienced some kind of a crisis in 2009, because their prices drop rapidly, but then rebounded. |
| C |
[scatter, hard, academic]
|
[1, L1] This is a scatter plot entitled “Born in 2016: Life Expectancy Gap by Gender and Income” that plots Women Life Expectancy at Birth (Years) by Men Life Expectancy at Birth (Years). The Women Life Expectancy at Birth is plotted on the vertical y-axis from 40 to 90 years. The Men Life Expectancy at Birth is plotted on the horizontal x-axis from 40 to 90 years. High Income Countries are plotted in dark green. Low Income Countries are plotted in light green. A 45 degree line from the origin represents Equal Life Expectancy. [2, L2] For low income countries, the average life expectancy is 60 years for men and 65 years for women. For high income countries, the average life expectancy is 77 years for men and 82 years for women. [3, L3] Overall, women have a slightly higher life expectancy than men. Women live around 5 to 10 years longer than men. The low income countries are more scattered than the high income countries. There is a visible gap between high and low income countries, indicated by the Income-Age Divide line. [4, L4] People living in low-income countries tend to have a lower life expectancy than the people living in high-income countries, likely due to many societal factors, including access to healthcare, food, other resources, and overall quality of life. People who live in lower income countries are more likely to experience deprivation and poverty, which can cause related health problems. |
4.3 Level 3: Perceptual and Cognitive Phenomena
At the third level, there are sentences whose semantic content refers to perceptual and cognitive phenomena appearing in the visual representation of the data.
When compared to, and defended against, other forms of data analysis (e.g., purely mathematical or statistical methods), visualization is often argued to confer some unique benefit to human readers.
That is, visualizations do not only “report” descriptive statistics of the data (as in Level 2), they also
Prices of particular Big Tech corporations seem to fluctuate but nevertheless increase over time. Years 2008-2009 are exceptions as we can see an extreme drop in prices of all given corporations.
The low income countries are more scattered than the high income countries. There is a visible gap between high and low income countries, indicated by the Income-Age Divide line.
These sentences convey the “overall gist” of complex trends and patterns (e.g., stock prices “seem to fluctuate but nevertheless increase”), synthesize multiple trends to identify exceptions (e.g., “years 2008-2009 are exceptions as we can see an extreme drop” of multiple graphed lines at that point in time), and do so in “natural”-sounding language, by referencing commonplace concepts (such as “fluctuate”, “extreme drop”, “visible gap”). N.b., “natural”-sounding articulation is necessary but insufficient for Level 3 membership, as it is also possible to articulate Level 1 or 2 content in a non-templatized fashion (§ 3.2.2).
4.4 Level 4: Contextual and Domain-Specific Insights
Finally, at the fourth level, there are sentences whose semantic content refers to contextual and domain-specific knowledge and experience. Consider the following two examples (Table 3.B.4 and 3.C.4).
The big drop in prices was caused by financial crisis of 2007-2008. The crisis culminated with the bankruptcy of Lehman Brothers on September 15, 2008 and an international banking crisis.
People living in low-income countries tend to have a lower life expectancy than the people living in high-income countries, likely due to many societal factors, including access to healthcare, food, other resources, and overall quality of life.
These sentences convey social and political explanations for an observed trend that depends on an individual reader’s subjective knowledge about particular world events: the 2008 financial crisis and global socio-economic trends, respectively. This semantic content is characteristic of what is often referred to as “insight” in visualization research. Although lacking a precise and agreed-upon definition [60, 95, 76, 20, 61], an insight is often an observation about the data that is complex, deep, qualitative, unexpected, and relevant [108]. Critically, insights depend on individual perceivers, their subjective knowledge, and domain-expertise. Level 4 is where the breadth of an individual reader’s knowledge and experience is brought to bear in articulating something “insightful” about the visualized data.
Lastly, we briefly note that data-driven predictions can belong to either Level 2, 3, or 4, depending on the semantic content contained therein. For example: a point-wise prediction at Level 2 (e.g., computing a stock’s future expected price using the backing dataset); a prediction about future overall trends at Level 3 (e.g., observing that a steadily increasing stock price will likely continue to rise); a prediction involving contextual or domain-specific knowledge at Level 4 (e.g., the outcome of an election using a variety of poll data, social indicators, and political intuition).
5 Applying the Model: Evaluating the Effectiveness of Visualization Descriptions
The foregoing conceptual model provides a means of making structured comparisons between different levels of semantic content and reader groups. To demonstrate how it can be applied to evaluate the effectiveness of visualization descriptions (i.e., whether or not they effectively convey meaningful information, and for whom), we conducted a mixed-methods evaluation in which 30 blind and 90 sighted readers first ranked the usefulness of descriptions authored at varying levels of semantic content, and then completed an open-ended questionnaire.
5.1 Evaluation Design
We selected 15 visualizations for the evaluation, curated to be representative of the categories from our prior survey (§ 3).
Specifically, we selected 5 visualizations for each of the three dimensions:
In addition to curating a representative set of visualizations, we also curated descriptions representative of each level of semantic content.
Participant-authored descriptions from our prior survey often did not contain content from all 4 levels or, if they did, this content was interleaved in a way that was not cleanly-separable for the purpose of a ranking task (Fig. 1).
Thus, for this evaluation, we curated and collated sentences from multiple participant-authored descriptions to create exemplar descriptions, such that each text chunk contained
“
Suppose that you are reading an academic paper about how life expectancy differs for people of different genders from countries with different levels of income. You encounter the following visualization. [Table 3.C]Which content do you think would be most useful to include in a textual description of this visualization?”
Additionally, blind readers were presented with a brief text noting that the hypothetically-encountered visualization was inaccessible via screen reader technology. In contrast to prior work, which has evaluated chart descriptions in terms of “efficiency,” “informativeness,” and “clarity” [39, 78], we intentionally left the definition of “useful” open to the reader’s interpretation. We hypothesize that “useful” descriptions may not be necessarily efficient (i.e., they may require lengthy explanation or background context), and that both informativeness and clarity are constituents of usefulness. In short, ranking “usefulness” affords a holistic evaluation metric. Participants assigned usefulness rankings to each of the 4 descriptions by selecting corresponding radio buttons, labeled 1 (least useful) to 4 (most useful). In addition to these 4 descriptions, we included a 5th choice as an “attention check”: a sentence whose content was entirely irrelevant to the chart to ensure participants were reading each description prior to ranking them. If a participant did not rank the attention check as least useful, we filtered out their response from our final analysis. We include the evaluation interfaces and questions with the Supplemental Material.
5.2 Participants
Participants consisted of two reader groups: 90 sighted readers recruited through the
5.2.1 Participant Recruitment
For sighted readers qualifications for participation included English language proficiency and no color vision deficiency, and blind readers were expected to be proficient with a screen reader, such as Job Access With Speech (JAWS), NonVisual Desktop Access (NVDA), or Apple’s VoiceOver.
Sighted readers were compensated at a rate of $10-12 per hour, for an approximately 20-minute task.
Blind readers were compensated at a rate of $50 per hour, for an approximately 1-hour task.
This difference in task duration was for two reasons.
First, participants recruited through
5.2.2 Participant Demographics
Among the 30 blind participants, 53% (n=16) reported their gender as male, 36% (n=11) as female, and 3 participants “preferred not to say.” The most common highest level of education attained was a Bachelor’s degree (60%, n=18), and most readers were between 20 – 40 years old (66%, n=20). The screen reader technology readers used to complete the study was evenly balanced: VoiceOver (n=10), JAWS (n=10), NVDA (n=9), and “other” (n=1). Among the 90 sighted participants, 69% reported their gender as male (n=62) and 31% as female (n=28). The most common highest level of education attained was a high school diploma (42%, n=38) followed by a Bachelor’s degree (40%, n=36), and most sighted readers were between 20 – 30 years old (64%, n=58).
On a 7-point Likert scale [1=strongly disagree, 7=strongly agree], blind participants reported having “a good understanding of data visualization concepts” (, ) as well as “a good understanding of statistical concepts and terminology” (, ). Sighted participants reported similar levels of understanding: (, ) and (, ), respectively. Sighted participants also considered themselves to be “proficient at reading data visualizations” (, ) and were able to “read and understand all of the visualizations presented in this study” (, ).
| blind readers | sighted readers |
|---|---|
 Data Table: Blind Readers' Rankings
Data Table: Blind Readers' Rankings
|
 Data Table: Sighted Readers' Rankings
Data Table: Sighted Readers' Rankings
|
| level comparisons | L1 by L2 | L1 by L3 | L1 by L4 | L2 by L3 | L2 by L4 | L3 by L4 |
| blind readers | ||||||
| sighted readers |
5.3 Quantitative Results
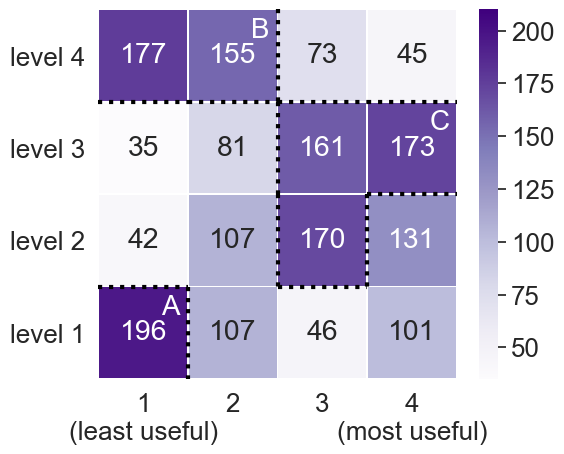
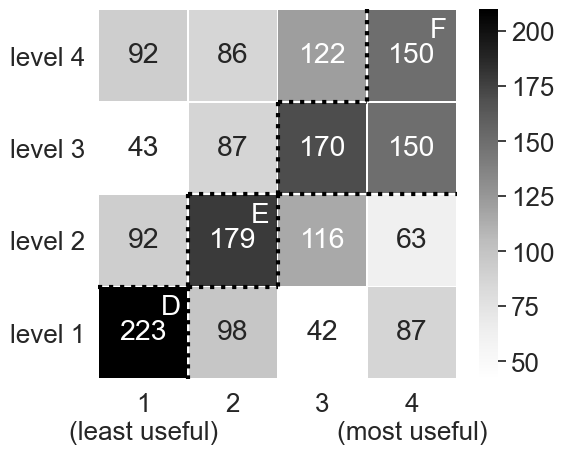
Quantitative results for the individual rankings (1,800 per blind and sighted reader groups) are summarized by the heatmaps in Table 4 (Upper Subtable), which aggregate the number of times a given content level was assigned a certain rank. Dotted lines in both blind and sighted heatmaps delineate regions exceeding a threshold — calculated by taking the mean plus half a standard deviation () resulting in a value of 139 and 136, respectively — and are labeled with a capital letter A – F.
These results exhibit significant differences between reader groups. For both reader groups, using Friedman’s Test (a non-parametric multi-comparison test for rank-order data) the p-value is , so we reject the null hypothesis that the mean rank is the same for all four semantic content levels [37]. Additionally, in Table 4 (Lower Subtable), we find significant ranking differences when making pair-wise comparisons between levels, via Nemenyi’s test (a post-hoc test commonly coupled with Friedman’s to make pair-wise comparisons). There appears to be strong agreement among sighted readers that higher levels of semantic content are more useful: Levels 3 and 4 are found to be most useful (Region 4.F), while Levels 1 and 2 are least useful (Regions 4.D and 4.E). Blind readers agree with each other to a lesser extent, but strong trends are nevertheless apparent. In particular, blind readers rank content and Levels 2 and 3 as most useful (Region 4.C), and semantic content at Levels 1 and 4 as least useful (Regions 4.A and 4.B).
When faceting these rankings by visualization type, topic, or difficulty we did not observe any significant differences, suggesting that both reader groups rank semantic content levels consistently, regardless of how the chart itself may vary. Noteworthy for both reader groups, the distribution of rankings for Level 1 is bimodal —– the only level to exhibit this property. While a vast majority of both blind and sighted readers rank Level 1 content as least useful, this level is ranked “most useful” in 101 and 87 instances by blind and sighted readers, respectively. This suggests that both reader groups have a more complicated perspective toward descriptions of a chart’s elemental and encoded properties; a finding we explore further by analyzing qualitative data.
5.4 Qualitative Results
In a questionnaire, we asked readers to use a 7-point Likert scale [1=strongly disagree, 7=strongly agree] to rate their agreement with a set of statements about their experience with visualizations. We also asked them to offer open-ended feedback about which semantic content they found to be most useful and why. Here, we summarize the key trends that emerged from these two different forms of feedback, from both blind readers (BR) and sighted readers (SR).
5.4.1 Descriptions Are Important to Both Reader Groups
All blind readers reported encountering inaccessible visualizations: either multiple times a week (43%, n=13), everyday (20%, n=6), once or twice a month (20%, n=6), or at most once a week (17%, n=5). These readers reported primarily encountering these barriers on social media (30%, n=9), on newspaper websites (13%, n=4), and in educational materials (53%, n=16) — but, most often, barriers were encountered in all of the above contexts (53%, n=16). Blind readers overwhelmingly agreed with the statements “I often feel that important public information is inaccessible to me, because it is only available in a visual format” (, ), and “Providing textual descriptions of data visualizations is important to me” (, ).
“I am totally blind, and virtually all data visualizations I encounter are undescribed, and as such are unavailable. This has been acutely made clear on Twitter and in newspapers around the COVID-19 pandemic and the recent U.S. election. Often, visualizations are presented with very little introduction or coinciding text. I feel very left out of the world and left out of the ability to confidently traverse that world. The more data I am unable to access, the more vulnerable and devalued I feel.” (BR5)
By contrast, sighted readers neither agreed nor disagreed regarding the inaccessibility of information conveyed visually (, ).
Similarly, they were split on whether they ever experienced barriers to reading visualizations, with 52% (n=47) reporting that they sometimes do (especially when engaging with a
5.4.2 Reader Groups Disagree About Contextual Content
A majority of blind readers (63%, n=19) were emphatic that descriptions should
5.4.3 Some Readers Prefer Non-Statistical Content
Overall, blind readers consistently ranked both Levels 2 and 3 as the most useful (Region 4.C). But, some readers explicitly expressed preference for the latter over the former, highlighting two distinguishing characteristics of Level 3 content: that it conveys not only descriptive statistics but overall perceptible trends, and that it is articulated in commonplace or “natural”-sounding language.
For instance, BR26 remarked that a visualization description is
5.4.4 Combinations of Content Levels Are Likely Most Useful
While roughly 12% readers from both blind and sighted groups indicated that a description should be as concise as possible, among blind readers, 40% (n=12) noted that the most useful descriptions would combine content from multiple levels.
This finding helps to explain the bimodality in Level 1 rankings we identified in the previous section.
According to BR9, Level 1 content is only useful if other information is also conveyed:
5.4.5 Some Automatic Methods Raise Ethical Concerns
Research on automatically generating visualization captions is often motivated by the goal of improving information access for people with visual disabilities [83, 27, 78, 84]. However, when deployed in real-world contexts, these methods may not confer their intended benefits, as one blind reader in our evaluation commented.
“A.I. attempting to convert these images is still in its infancy. Facebook and Apple auto-descriptions of general images are more of a timewaster than useful. As a practical matter, if I find an inaccessible chart or graph, I just move on.” (BP22)
Similarly, another participant (BR26) noted that if a description were to only describe a visualization’s encodings then
6 Discussion and Future Work
Our four-level model of semantic content — and its application to evaluating the usefulness of descriptions — has practical implications for the design of accessible data representations, and theoretical implications for the relationship between visualization and natural language.
6.1 Natural Language As An Interface Into Visualization
Divergent reader preferences for semantic content suggests that it is helpful to think of natural language — not only as an interface for constructing and exploring visualizations [93, 36, 89] — but also as an interface into visualization, for
6.2 Natural Language As Coequal With Visualization
In closing, we turn to a discussion of our model’s implications for visualization theory.
Not only can we think of natural language as an interface into visualization (as above), but also as an interface into data itself; coequal with and complementary to visualization.
For example, some semantic content (e.g., Level 2 statistics or Level 4 explanations) may be best conveyed via language, without any reference to visual modalities [82, 43], while other content (e.g., Level 3 clusters) may be uniquely suited to visual representation.
This coequal framing is not a departure from orthodox visualization theory, but rather a return to its linguistic and semiotic origins.
Indeed, at the start of his foundational
Within the contemporary linguistic tradition, subfields like syntax, semantics, and pragmatics suggest opportunities for further analysis at each level of our model. And, since our model focuses on English sentences and canonical chart types, extensions to other languages and bespoke charts may be warranted.
Within the semiotic tradition, Christian Metz (a contemporary of Bertin’s) emphasized the
Acknowledgements
For their valuable feedback, we thank Emilie Gossiaux, Chancey Fleet, Michael Correll, Frank Elavsky, Beth Semel, Stephanie Tuerk, Crystal Lee, and the MIT Visualization Group. This work was supported by National Science Foundation GRFP-1122374 and III-1900991.References
- [1] (2017) World Blindness and Visual Impairment. Community Eye Health. ISSN 0953-6833, Link Cited by: §1.
- [2] (2020) Communicative Visualizations as a Learning Problem. In TVCG, (en). Cited by: §2.3.2.
- [3] (2020) Inventorizing, Situating, Transforming: Social Semiotics And Data Visualization. In Data Visualization in Society, M. Engebretsen and H. Kennedy (Eds.), Cited by: §6.2.
- [4] (2016) Mind-Dependent Kinds. In Journal of Social Ontology, Cited by: §4.3.
- [5] (2005) Low-level Components Of Analytic Activity In Information Visualization. In INFOVIS, Cited by: §2.3.1.
- [6] (2018) Chart-Text: A Fully Automated Chart Image Descriptor. arXiv. Cited by: §2.1.1.
- [7] (2000) Instrumental Interaction: An Interaction Model For Designing Post-WIMP User Interfaces. In CHI, , Link Cited by: §1, §6.1.
- [8] (2004) Designing Interaction, Not Interfaces. In AVI, , Link Cited by: §1, §6.1.
- [9] Making Images Accessible. (en-US). Note: http://diagramcenter.org/making-images-accessible.html/ Link Cited by: §2.2.1.
- [10] (2021) “It’s Complicated”: Negotiating Accessibility and (Mis)Representation in Image Descriptions of Race, Gender, and Disability. In CHI, Cited by: §2.2.2.
- [11] (2020) SARS-CoV-2 Coronavirus. Note: http://ctbergstrom.com/covid19.html Link Cited by: Teaser.
- [12] (1983) Semiology of Graphics. University of Wisconsin Press. Cited by: §1, §4.1, §6.2.
- [13] (2010) VizWiz: Nearly Real-time Answers To Visual Questions. In UIST, Cited by: §2.2.2.
- [14] (2017) The Effects of ”Not Knowing What You Don’t Know” on Web Accessibility for Blind Web Users. In ASSETS, Cited by: §5.2.
- [15] (2016) Beyond Memorability: Visualization Recognition and Recall. In TVCG, Cited by: §3.2.1.
- [16] (2013) What Makes a Visualization Memorable?. In TVCG, Cited by: §3.2.1.
- [17] (2013) A Multi-Level Typology of Abstract Visualization Tasks. In TVCG, (en). Link Cited by: §2.3.1.
- [18] (2020) Signs and Sight: Jacques Bertin and the Visual Language of Structuralism. Grey Room. Link Cited by: §6.2.
- [19] (2020-08) Writing Alt Text for Data Visualization. (en). Link Cited by: §2.2.1.
- [20] (2009) Defining Insight for Visual Analytics. In CG&A, Cited by: §4.4.
- [21] (2017) Applications of Color in Design for Color-Deficient Users. Ergonomics in Design (en). ISSN 1064-8046, Link Cited by: §1.
- [22] (2019) Neural Caption Generation Over Figures. In UbiComp/ISWC ’19 Adjunct, Link Cited by: §2.1.1.
- [23] (2020) Figure Captioning with Relation Maps for Reasoning. In WACV, (en). Cited by: §2.1.1.
- [24] (2019) Figure Captioning with Reasoning and Sequence-Level Training. arXiv. Link Cited by: §2.1.1.
- [25] (2019) Visualizing for the Non-Visual: Enabling the Visually Impaired to Use Visualization. In CGF, (en). Cited by: §1, §2.2.
- [26] (2008) Generating textual summaries of bar chartsGenerating Textual Summaries Of Bar Charts. In INLG, (en). Cited by: §4.2.
- [27] (2012) Summarizing Information Graphics Textually. In Computational Linguistics, Cited by: §1, §2.2, §2.3.1, §5.4.5.
- [28] (2020) Vital Coronavirus Information Is Failing the Blind and Visually Impaired. Vice. Link Cited by: §1, Teaser.
- [29] (2021) Chartability. Note: https://chartability.fizz.studio/ Cited by: §2.2.1.
- [30] (2005) Exploring And Exploiting The Limited Utility Of Captions In Recognizing Intention In Information Graphics. In ACL, Cited by: §2.2.
- [31] (2007) A Browser Extension For Providing Visually Impaired Users Access To The Content Of Bar Charts On The Web. In WEBIST, Cited by: §2.2.
- [32] (2019) Creating Accessible SVGs. (en-US). Link Cited by: §2.2.1.
- [33] (2021) Things which garner a ton of glowing reviews from mainstream outlets without being of much use to disabled people. For instance, Facebook’s auto image descriptions, much loved by sighted journos but famously useless in the Blind community. Twitter. Note: https://twitter.com/ChanceyFleet/status/1349211417744961536 Cited by: §5.4.5.
- [34] (2020) An Introduction To Accessible Data Visualizations With D3.js. (en). Link Cited by: §2.2.1.
- [35] (2011) Graph Literacy: A Cross-cultural Comparison. In Medical Decision Making, Cited by: §2.3.1.
- [36] (2015) DataTone: Managing Ambiguity in Natural Language Interfaces for Data Visualization. In UIST, Cited by: §6.1.
- [37] (2010) Advanced Nonparametric Tests For Multiple Comparisons In The Design Of Experiments In Computational Intelligence And Data Mining: Experimental Analysis Of Power. Information Sciences (en). Cited by: §5.3.
- [38] (2012) VTK. The Architecture of Open Source Applications. Cited by: §2.1.2.
- [39] (2008) Effective Practices for Description of Science Content within Digital Talking Books. Technical report The WGBH National Center for Accessible Media (en). Note: https://www.wgbh.org/foundation/ncam/guidelines/effective-practices-for-description-of-science-content-within-digital-talking-books Link Cited by: §1, §2.2.1, §5.1.
- [40] (2021) Computer Vision and Conflicting Values: Describing People with Automated Alt Text. arXiv. Cited by: §5.4.5.
- [41] (2011) Guidelines and Standards for Tactile Graphics. Technical report Braille Authority of North America. Note: http://www.brailleauthority.org/tg/ Link Cited by: §1.
- [42] (2019) Toward Interface Defaults for Vague Modifiers in Natural Language Interfaces for Visual Analysis. In VIS, Cited by: §2.3.2.
- [43] (2019) Would You Like A Chart With That? Incorporating Visualizations into Conversational Interfaces. In VIS, Cited by: §2.3.2, §6.2.
- [44] (2011) Visualization Rhetoric: Framing Effects in Narrative Visualization. In TVCG, (en). Cited by: §6.2.
- [45] (2013) Contextifier: automatic generation of annotated stock visualizations. In CHI, Cited by: §4.4.
- [46] (2015) Content, Context, and Critique: Commenting on a Data Visualization Blog. In CSCW, Cited by: §6.2.
- [47] (2018) FigureQA: An Annotated Figure Dataset for Visual Reasoning. arXiv. Cited by: §2.1.1, §4.1.
- [48] (2017-04) Deep Visual-Semantic Alignments for Generating Image Descriptions. In TPAMI, Cited by: §2.1.1.
- [49] (2007) Literature Fingerprinting: A New Method for Visual Literary Analysis. In VAST, Cited by: Figure 1, §3.2.2.
- [50] (2020-04) Answering Questions about Charts and Generating Visual Explanations. In CHI, (en). Cited by: §2.3.2.
- [51] (2018) Facilitating Document Reading by Linking Text and Tables. In UIST, Cited by: §2.3.2.
- [52] (2021) Towards Understanding How Readers Integrate Charts and Captions: A Case Study with Line Charts. In CHI, (en). Cited by: §2.3.2.
- [53] (2021) Accessible Visualization: Design Space, Opportunities, and Challenges. In CGF, Cited by: §1.
- [54] (2018-04) Frames and Slants in Titles of Visualizations on Controversial Topics. In CHI, (en). Cited by: §2.3.2.
- [55] (2019-05) Trust and Recall of Information across Varying Degrees of Title-Visualization Misalignment. In CHI, (en). Cited by: §2.3.2.
- [56] (2014) Extracting References Between Text And Charts Via Crowdsourcing. In CHI, Cited by: §2.2.2.
- [57] (1989) Understanding Charts and Graphs. Applied Cognitive Psychology (en). Cited by: §2.3.1.
- [58] (2017) Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. In IJCV, Cited by: §2.1.1.
- [59] (2020) Automatic Annotation Synchronizing with Textual Description for Visualization. In CHI, (en). Cited by: §2.1.1.
- [60] (2020-08) What are Data Insights to Professional Visualization Users?. arXiv. Link Cited by: §4.4.
- [61] (2020) Characterizing Automated Data Insights. arXiv. Cited by: §4.4.
- [62] (2021) Viral Visualizations: How Coronavirus Skeptics Use Orthodox Data Practices to Promote Unorthodox Science Online. In CHI, Cited by: §6.2.
- [63] (2016) Vlat: Development Of A Visualization Literacy Assessment Test. In TVCG, Cited by: §2.3.1.
- [64] (2014) Microsoft COCO: Common Objects in Context. In ECCV, (en). Cited by: §2.1.1.
- [65] (2020) COVID-19 Statistics Tracker. (en). Note: https://cvstats.net Link Cited by: §1.
- [66] (2020) Position: Visual Sentences: Definitions and Applications. In VIS, Cited by: §2.3.1.
- [67] (2019-10) Sociotechnical Considerations for Accessible Visualization Design. In VIS, Cited by: §1, §2.2, §5.2.1, §5.4.5.
- [68] (2012) Visual Semiotics Uncertainty Visualization: An Empirical Study. In TVCG, Cited by: §6.2.
- [69] (2017) Understanding Blind People’s Experiences with Computer-Generated Captions of Social Media Images. In CHI, Cited by: §2.1.1, §5.4.5.
- [70] (2017) Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing. In CHI, (en). Cited by: §4.3.
- [71] (2014) Evaluating The Accessibility Of Line Graphs Through Textual Summaries For Visually Impaired Users. In ASSETS, Cited by: §2.1.1, §2.2.
- [72] (2015) Guiding Novice Web Workers in Making Image Descriptions Using Templates. In TACCESS, Cited by: §2.1.1, §2.2.2, §4.3.
- [73] (2018) Rich Representations of Visual Content for Screen Reader Users. In CHI, Cited by: §2.2.
- [74] (2014) Curiosity, Creativity, and Surprise as Analytic Tools: Grounded Theory Method. In Ways of Knowing in HCI, J. S. Olson and W. A. Kellogg (Eds.), Cited by: §3.1, §3.
- [75] (2021) NL4DV: A Toolkit for Generating Analytic Specifications for Data Visualization from Natural Language Queries. In TVCG, (en). Cited by: §2.3.2.
- [76] (2006) Toward Measuring Visualization Insight. In CG&A, Cited by: §4.4.
- [77] (2018) Optimizing Colormaps With Consideration For Color Vision Deficiency To Enable Accurate Interpretation Of Scientific Data. PLOS ONE (en). Cited by: §1.
- [78] (2020) Chart-to-Text: Generating Natural Language Descriptions for Charts by Adapting the Transformer Model. arXiv. Cited by: §1, §2.1.1, §2.2, §4.2, §4.3, §5.1, §5.4.5.
- [79] (2013) Towards More Accessible Visualizations for Color-Vision-Deficient Individuals. In CiSE, Cited by: §1.
- [80] (2019) The Curious Case of Combining Text and Visualization. In EuroVis, (en). Cited by: §2.3.2.
- [81] (2017) Reverse-Engineering Visualizations: Recovering Visual Encodings from Chart Images. In CGF, Link Cited by: §3.2.1, §4.1.
- [82] (2021) Examining Visual Semantic Understanding in Blind and Low-Vision Technology Users. In CHI, Cited by: §6.2.
- [83] (2021) Generating Accurate Caption Units for Figure Captioning. In WWW, (en). Cited by: §2.1.1, §2.2, §5.4.5.
- [84] (2020) A Formative Study on Designing Accurate and Natural Figure Captioning Systems. In CHI EA, Cited by: §1, §2.1.1, §2.2.2, §2.2, §2.3.1, §5.4.5.
- [85] (1979) A Sentence Verification Technique For Measuring Reading Comprehension. Journal of Reading Behavior. Cited by: §2.3.1.
- [86] (2001) Developing Reading And Listening Comprehension Tests Based On The Sentence Verification Technique (SVT). In Journal of Adolescent & Adult Literacy, Cited by: §2.3.1.
- [87] (2017) Vega-Lite: A Grammar of Interactive Graphics. In TVCG, Cited by: §2.1.2, §3.2.1, §4.1.
- [88] (2020) Why Accessibility Is at the Heart of Data Visualization. (en). Link Cited by: §2.2.1.
- [89] (2016) Eviza: A Natural Language Interface for Visual Analysis. In UIST, Cited by: §6.1.
- [90] (2019) Inferencing Underspecified Natural Language Utterances In Visual Analysis. In IUI, Cited by: §2.3.2.
- [91] (2021) Understanding Screen-Reader Users’ Experiences with Online Data Visualizations. In ASSETS, Cited by: §2.2.
- [92] (2019) Augmenting Visualizations with Interactive Data Facts to Facilitate Interpretation and Communication. In TVCG, (en). Cited by: §3.2.2, §4.2, §4.2.
- [93] (2021) Collecting and Characterizing Natural Language Utterances for Specifying Data Visualizations. In CHI, (en). Cited by: §2.3.2, §6.1.
- [94] (2020) Accessible Covid-19 Tracker Enables A Way For Visually Impaired To Stay Up To Date. Disability Compliance for Higher Education (en). Cited by: §1.
- [95] (2017) Extracting Top-K Insights from Multi-dimensional Data. In SIGMOD, (en). Cited by: §4.4.
- [96] (2014) Bokeh: Python Library For Interactive Visualization. Bokeh Development Team. Cited by: §2.1.2.
- [97] (2013) Understanding Visualization: A Formal Approach Using Category Theory and Semiotics. In TVCG, Cited by: §6.2.
- [98] (2015) Show and Tell: A Neural Image Caption Generator. In CVPR, (en). Link Cited by: §2.1.1.
- [99] (2019) WAI Web Accessibility Tutorials: Complex Images. Note: https://www.w3.org/WAI/tutorials/images/complex/ Link Cited by: §1, §2.1.2, §2.2.1.
- [100] (2020) DataShot: Automatic Generation of Fact Sheets from Tabular Data. In TVCG, Cited by: §3.2.2, §4.2.
- [101] (2017) Accessible SVG Line Graphs. (en). Note: https://tink.uk/accessible-svg-line-graphs/ Link Cited by: §2.2.1.
- [102] (2018) Accessible SVG Flowcharts. (en). Link Cited by: §2.2.1.
- [103] (2019) Towards a Semiotics of Data Visualization – an Inventory of Graphic Resources. In IV, Cited by: §6.2.
- [104] (2005) The Grammar of Graphics. Statistics and Computing, Springer-Verlag (en). Cited by: §4.1.
- [105] (2021) Understanding Data Accessibility for People with Intellectual and Developmental Disabilities. In CHI 2021, (en). Cited by: §1.
- [106] (2020) The Curse of Knowledge in Visual Data Communication. In TVCG, Cited by: §2.3.2.
- [107] (2016) Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. arXiv. Cited by: §2.1.1.
- [108] (2008) Understanding and Characterizing Insights: How Do People Gain Insights Using Information Visualization?. In BELIV, (en). Cited by: §4.4.