
Sherlock: A Deep Learning Approach to Semantic Data Type Detection
Madelon Hulsebos MIT Media Lab
Kevin Hu MIT Media Lab
Michiel Bakker MIT Media Lab
Emanuel Zgraggen MIT CSAIL

Tim Kraska MIT CSAIL
Çağatay Demiralp MIT CSAIL
César Hidalgo MIT Media Lab
ACM Knowledge Discovery and Data Mining (KDD), 2019
Abstract
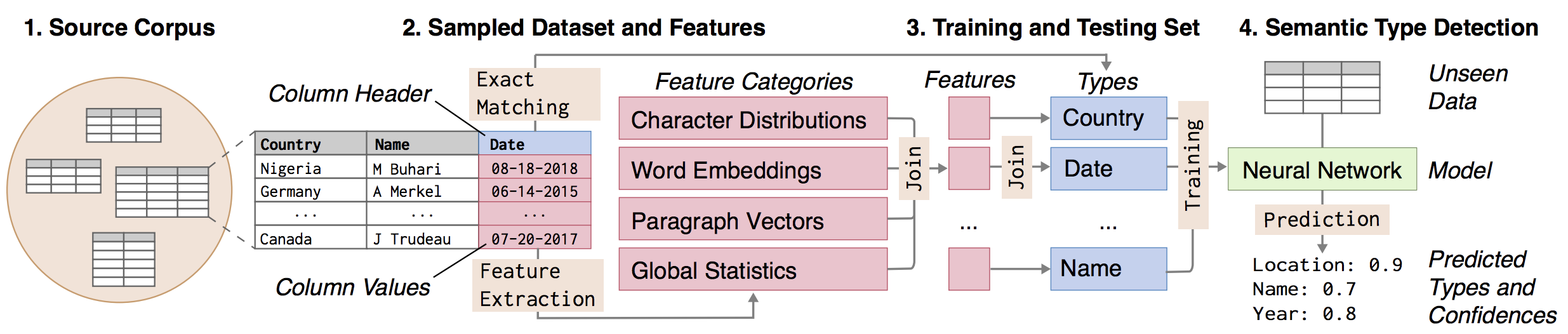
Correctly detecting the semantic type of data columns is crucial for data science tasks such as automated data cleaning, schema matching, and data discovery. Existing data preparation and analysis systems rely on dictionary lookups and regular expression matching to detect semantic types. However, these matching-based approaches often are not robust to dirty data and only detect a limited number of types. We introduce Sherlock, a multi-input deep neural network for detecting semantic types. We train Sherlock on 686,765 data columns retrieved from the VizNet corpus by matching 78 semantic types from DBpedia to column headers. We characterize each matched column with 1,588 features describing the statistical properties, character distributions, word embeddings, and paragraph vectors of column values. Sherlock achieves a support-weighted F1 score of 0.89, exceeding that of machine learning baselines, dictionary and regular expression benchmarks, and the consensus of crowdsourced annotations.