
Assessing the Impact of Automated Suggestions on Decision Making: Domain Experts Mediate Model Errors but Take Less Initiative

ACM Human Factors in Computing Systems (CHI), 2021
Abstract
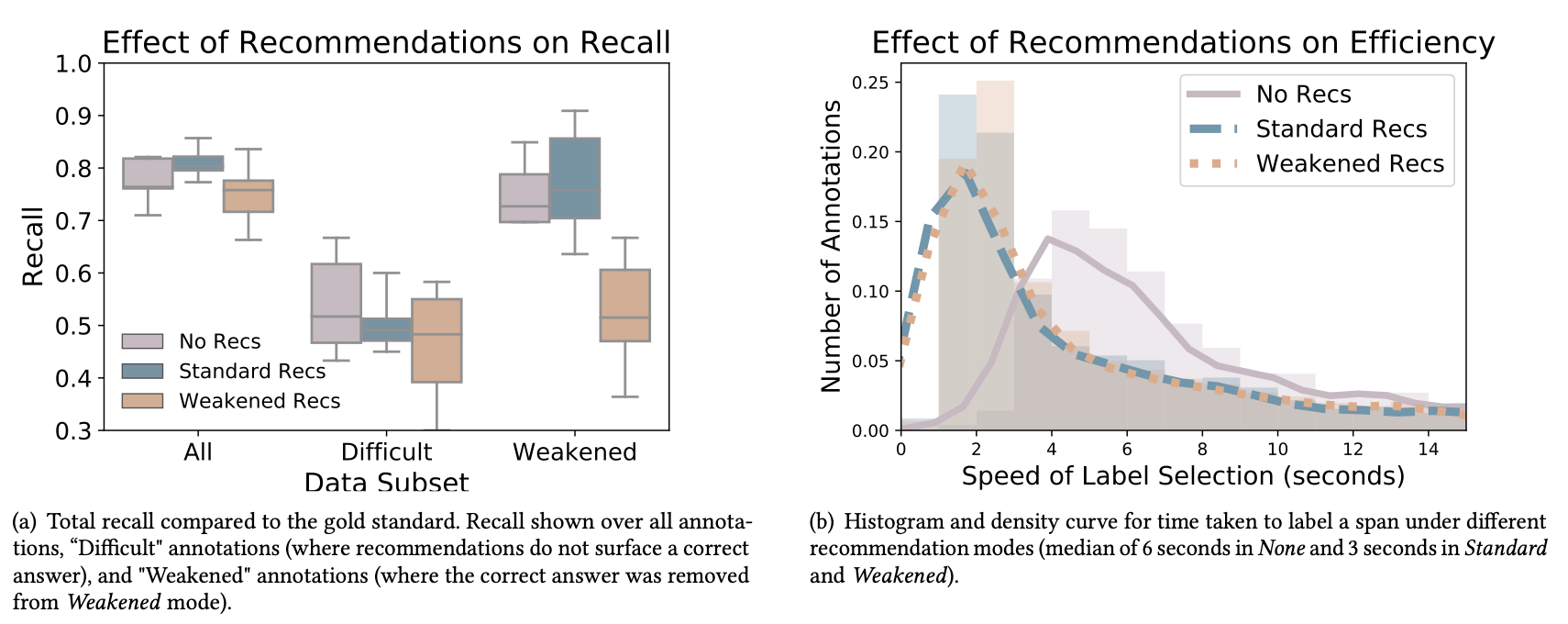
Automated decision support can accelerate tedious tasks as users can focus their attention where it is needed most. However, a key concern is whether users overly trust or cede agency to automation. In this paper, we investigate the effects of introducing automation to annotating clinical texts — a multi-step, error-prone task of identifying clinical concepts (e.g., procedures) in medical notes, and mapping them to labels in a large ontology. We consider two forms of decision aid: recommending which labels to map concepts to, and pre-populating annotation suggestions. Through laboratory studies, we find that 18 clinicians generally build intuition of when to rely on automation and when to exercise their own judgement. However, when presented with fully pre-populated suggestions, these expert users exhibit less agency: accepting improper mentions, and taking less initiative in creating additional annotations. Our findings inform how systems and algorithms should be designed to mitigate the observed issues.